Anıl Helvacı
|
2022-08-15
45 mins to read
An article explaining how a lending protocol like Ethereum's Compound Finance is implemented on Agoric
Read More
André Barbosa
2018-12-04
30 mins to read
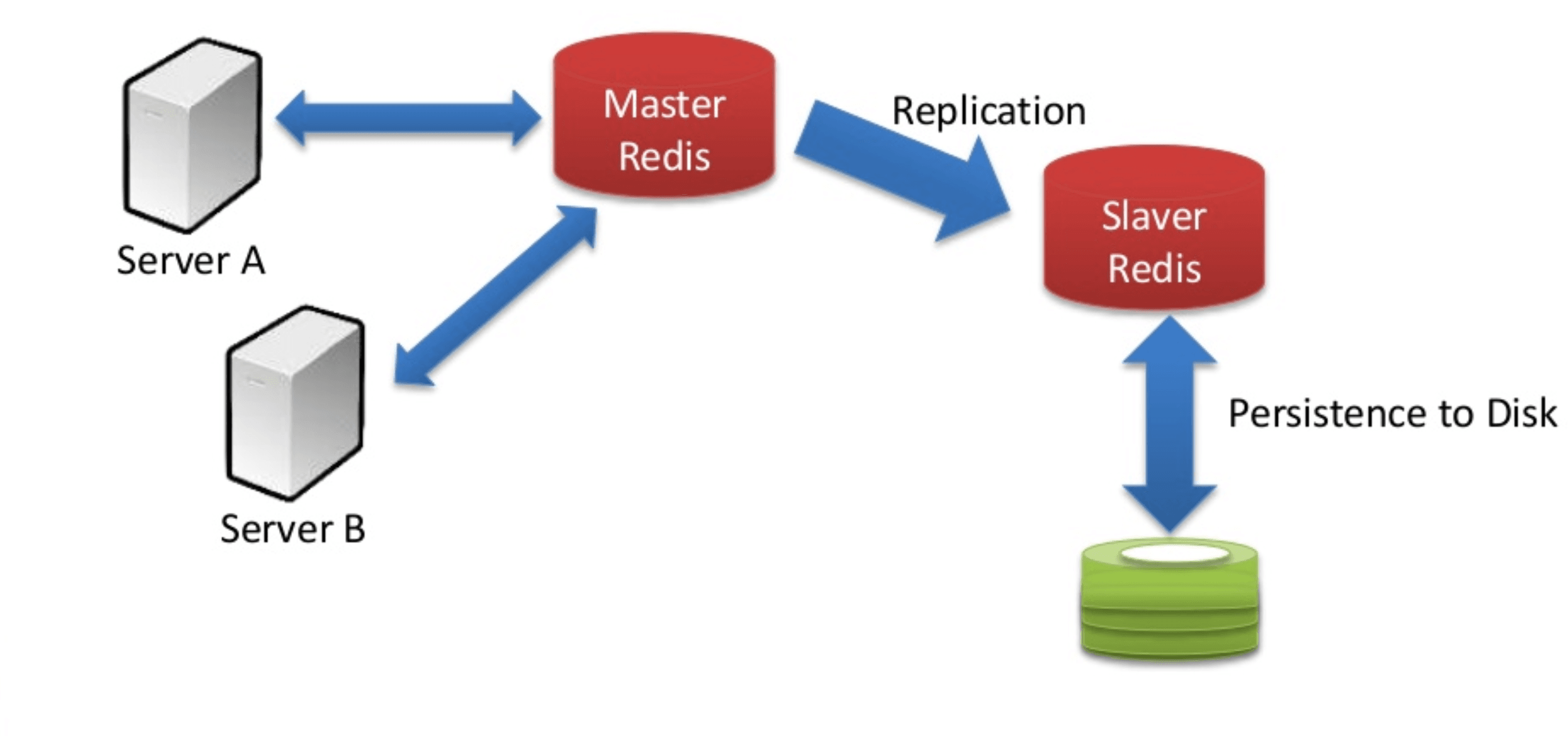
This will be a brief article on how we had to integrate a Redis-based cache for one of our client’s services.
Luís Freitas
2021-05-28
35 mins to read
Make it make sense! React states need not be “trapped” in a component and its children.
Decline
Accept